Go的调度:第三部分 - 并发
[译] Scheduling In Go : Part III - Concurrency
序幕
这是分三部分的系列文章中的第三篇,它将提供对Go调度器背后的机制和语义的理解。这篇文章专注于并发。
三个部分系列的索引:
介绍
当我解决问题时,特别是一个新问题时,我最初不会考虑并发是否合适。我首先依次寻找解决方案,并确保它能正常工作。然后,在经过可读性和技术审查之后,我将开始问并发是否合理可行。有时,很明显并发是一个很好的选择,而有时却不太清楚。
在本系列的第一部分中,我解释了OS调度器的机制和语义,如果您打算编写多线程代码,我认为它们很重要。在第二部分中,我解释了Go调度器的语义,我认为这对于理解如何在Go中编写并发代码很重要。在本文中,我将开始将OS和Go调度器的机制和语义放在一起,以更深入地了解什么是并发。
这篇文章的目标是:
- 提供有关必须考虑的语义的指导,以确定工作负载是否适合使用并发。
- 向您展示不同类型的工作负载如何改变语义,从而改变您要做出的工程决策。
什么是并发
并发意味着“乱序”执行。采取一组原本会按顺序执行的指令,并找到一种无序执行它们的方法,但仍会产生相同的结果。对于摆在您面前的问题,显而易见的是,无序执行会增加价值。当我说价值时,我的意思是为复杂性成本增加足够的性能。根据您的问题,可能无法执行乱序执行,甚至没有道理。
同样重要的是要了解并发与并行性并不相同。并行是指同时执行两个或更多指令。这是与并发不同的概念。只有在您拥有至少两个可用的操作系统(OS)和硬件线程,并且您至少有两个Goroutines时才可以并行处理,每个Goroutines在每个OS /硬件线程上独立执行指令。
图1:并发与并行
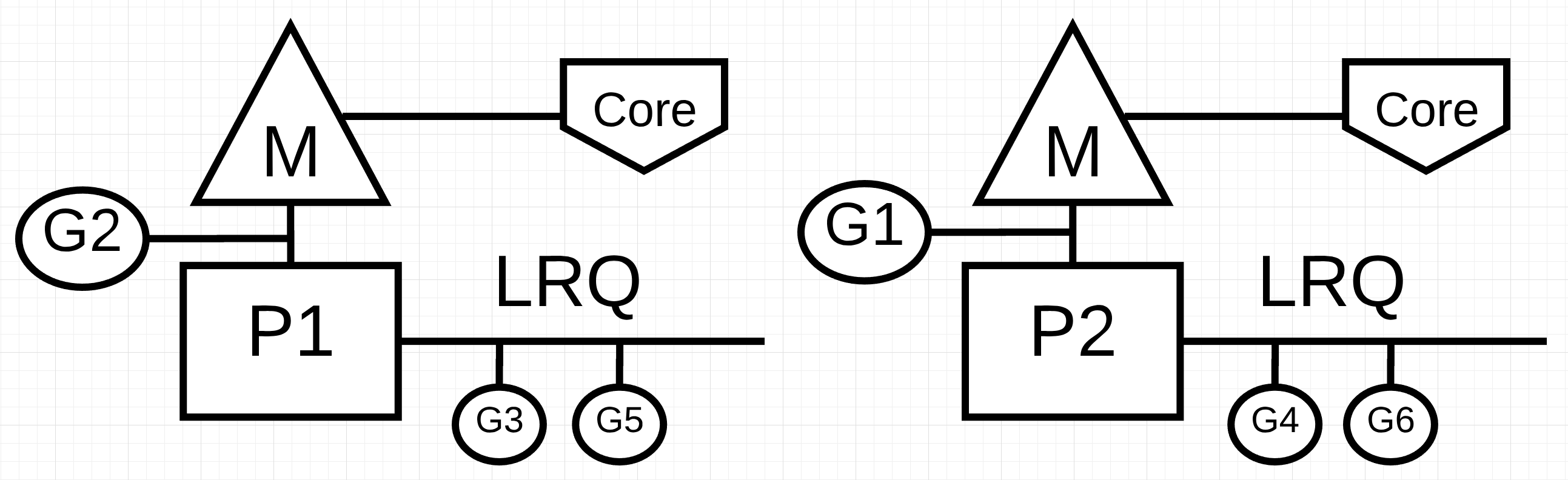
在图1中,您可以看到两个逻辑处理器(P)的示意图,每个逻辑处理器(P)的独立OS线程(M)连接到计算机上的独立硬件线程(Core)。您会看到两个Goroutine(G1和G2)正在并行执行,同时在各自的OS /硬件线程上执行它们的指令。在每个逻辑处理器中,三个Goroutine轮流共享它们各自的OS线程。所有这些Goroutine都并发运行,以不特定的顺序执行它们的指令,并在OS线程上共享时间。
麻烦的是,有时在没有并行的情况下利用并发实际上会减慢您的吞吐量。有趣的是,有时将并行性与并行性结合使用不会给您带来比您原本可以实现的更大的性能提升。
工作负载
您怎么知道何时可能出现乱序执行或者是有意义的?了解您的问题正在处理的工作负载类型是一个很好的起点。在考虑并发性时,需要了解两种类型的工作负载。
- **CPU密集型:**这是一个永远不会导致Goroutines自然地进入和退出等待状态的工作负载。这是不断进行计算的工作。计算Pi到第N位的线程将是CPU密集型的。
- **IO密集型:**这是导致Goroutines自然进入等待状态的工作负载。这项工作包括请求通过网络访问资源,或对操作系统进行系统调用或等待事件发生。需要读取文件的Goroutine将是IO密集型。我将包括同步事件(互斥量,原子),这些事件会导致Goroutine等待作为该类别的一部分。
对于CPU密集型的工作负载,您需要并行性以利用并发性。单个OS /硬件线程处理多个Goroutine效率不高,因为Goroutine不会作为工作负荷的一部分移入和移出等待状态。Goroutine的数量多于OS /硬件线程的数量,这会减慢工作负载的执行速度,这是因为将Goroutine移入和移出OS线程的延迟成本(所花费的时间)。上下文切换正在为您的工作负载创建一个“世界停止”事件,因为在切换过程中,如果没有其他工作负载,则不会执行任何工作负载。
使用IO密集型的工作负载,您无需并行即可使用并发。单个OS /硬件线程可以高效地处理多个Goroutine,因为Goroutine作为工作量的一部分自然会进入和退出等待状态。Goroutine的数量多于OS /硬件线程的数量,可以加快工作负载的执行速度,因为在操作系统线程上上下移动Goroutine的延迟成本不会产生“ Stop The World”事件。您的工作负载自然停止了,这允许不同的Goroutine有效利用相同的OS /硬件线程,而不是让OS /硬件线程闲置。
您如何知道每个硬件线程有多少个Goroutine提供最佳吞吐量?Goroutine太少,您有更多的空闲时间。Goroutine太多,您有更多的上下文切换延迟时间。这是您可以考虑的内容,但超出了此特定文章的范围。
现在,重要的是查看一些代码以巩固您的能力,以识别工作负荷何时可以利用并发,何时不能利用并发以及是否需要并行性。
数字累加
我们不需要复杂的代码来可视化和理解这些语义。查看以下命名add为整数集合的函数。
清单1 https://play.golang.org/p/r9LdqUsEzEz
|
|
在第36行的清单1中,声明了一个名为 add 的函数,该函数接收一个整数集合并返回该集合的总和。它从第37行开始,声明变量 v 来保存总和。然后在第38行,该函数线性遍历该集合,并且在第39行将每个数字加到当前总和。最后在第41行,该函数将最终总和返回给调用方。
问题:该add函数是否适合于无序执行的工作负载?我相信答案是肯定的。整数的集合可以分解成较小的列表,并且这些列表可以同时处理。一旦所有较小的列表被求和,就可以将总和集加在一起以产生与顺序版本相同的答案。
但是,我想到了另一个问题。为了获得最佳吞吐量,应独立创建和处理多少个较小的列表?要回答这个问题,您必须知道add正在执行哪种工作负载。该add函数正在执行CPU密集型的工作负载,因为该算法执行的是纯数学运算,并且它所做的任何操作都不会导致goroutine进入自然等待状态。这意味着每个OS /硬件线程仅使用一个Goroutine即可获得良好的吞吐量。
下面的清单2是我的并发版本add。
注意:编写并发版本的add时,可以采用几种方法和选项。现在不要挂在我的特定实现上。如果您有一个可读性更高的版本,其性能相同或更好,我希望与您分享。
清单2 https://play.golang.org/p/r9LdqUsEzEz
|
|
在清单2中,展示了该addConcurrent函数,它是该add函数的并发版本。并发版本使用26行代码,而不是非并发版本使用5行代码。有很多代码,所以我只强调要理解的重要内容。
**第48行:**每个Goroutine将获得自己独特但较小的数字列表以进行添加。列表的大小是通过将集合的大小除以Goroutine的数量来计算的。
**第53行:**创建Goroutine池以执行添加工作。
**第57-59行:**最后一个Goroutine将添加剩余的可能比其他Goroutine大的数字列表。
**第66行:**较小列表的总和加在一起成为最终总和。
并发版本肯定比顺序版本更复杂,但是值得吗?回答这个问题的最好方法是创建一个基准。对于这些基准测试,我使用了1000万个数字的集合,并且关闭了垃圾收集器。有使用该add功能的顺序版本和使用该功能的并发版本addConcurrent。
清单3
|
|
清单3显示了基准功能。这是所有Goroutines仅具有一个OS /硬件线程时的结果。顺序版本正在使用1个Goroutine,而并行版本正在使用runtime.NumCPU或8个Goroutine。在这种情况下,并发版本利用并发而没有并行性。
清单4
10 Million Numbers using 8 goroutines with 1 core
2.9 GHz Intel 4 Core i7
Concurrency WITHOUT Parallelism
-----------------------------------------------------------------------------
$ GOGC=off go test -cpu 1 -run none -bench . -benchtime 3s
goos: darwin
goarch: amd64
pkg: github.com/ardanlabs/gotraining/topics/go/testing/benchmarks/cpu-bound
BenchmarkSequential 1000 5720764 ns/op : ~10% Faster
BenchmarkConcurrent 1000 6387344 ns/op
BenchmarkSequentialAgain 1000 5614666 ns/op : ~13% Faster
BenchmarkConcurrentAgain 1000 6482612 ns/op
注意:在本地计算机上运行基准测试很复杂。有太多因素可能导致基准测试不准确。确保您的计算机尽可能空闲,并运行几次基准测试。您要确保结果一致。由测试工具运行两次基准测试可以使该基准测试获得最一致的结果。
清单4中的基准测试表明,当所有Goroutines仅具有一个OS /硬件线程时,Sequential版本比Concurrent大约快10%到13%。这是我所期望的,因为并发版本具有在单个OS线程上进行上下文切换和对Goroutine进行管理的开销。
这是每个Goroutine都有单独的OS /硬件线程时的结果。顺序版本正在使用1个Goroutine,而并行版本正在使用runtime.NumCPU或8个Goroutine。在这种情况下,并发版本将并发与并行性结合起来。
清单5
10 Million Numbers using 8 goroutines with 8 cores
2.9 GHz Intel 4 Core i7
Concurrency WITH Parallelism
-----------------------------------------------------------------------------
$ GOGC=off go test -cpu 8 -run none -bench . -benchtime 3s
goos: darwin
goarch: amd64
pkg: github.com/ardanlabs/gotraining/topics/go/testing/benchmarks/cpu-bound
BenchmarkSequential-8 1000 5910799 ns/op
BenchmarkConcurrent-8 2000 3362643 ns/op : ~43% Faster
BenchmarkSequentialAgain-8 1000 5933444 ns/op
BenchmarkConcurrentAgain-8 2000 3477253 ns/op : ~41% Faster
清单5中的基准测试表明,当每个Goroutine有单独的OS /硬件线程时,并发版本比顺序版本快41%至43%。这是我所期望的,因为所有Goroutine现在都并行运行,八个Goroutine同时执行其并发工作。
排序
重要的是要了解并非所有受CPU约束的工作负载都适用于并发。当分解工作和/或合并所有结果非常昂贵时,这是基本正确的。使用称为冒泡排序的排序算法可以看到一个示例。查看以下在Go中实现Bubble排序的代码。
清单6 https://play.golang.org/p/S0Us1wYBqG6
|
|
在清单6中,有一个用Go编写的Bubble排序示例。这种排序算法会在每次通过时扫描整数交换值的集合。根据列表的顺序,在对所有内容进行排序之前,可能需要多次通过集合。
问题:该bubbleSort功能是否适合于无序执行的工作负载?我相信答案是否定的。整数的集合可以分解为较小的列表,并且这些列表可以同时排序。但是,在完成所有并发工作之后,没有有效的方法将较小的列表分类在一起。这是冒泡排序的并发版本的示例。
清单8
|
|
在清单8中,提供了该bubbleSortConcurrent函数,它是该bubbleSort函数的并发版本。它使用多个Goroutines同时对列表的各个部分进行排序。但是,剩下的是按块排序的值的列表。给定一个由36个数字组成的列表,分为12组,如果整个列表不在第25行中再次排序,则将成为结果列表。
清单9
Before:
25 51 15 57 87 10 10 85 90 32 98 53
91 82 84 97 67 37 71 94 26 2 81 79
66 70 93 86 19 81 52 75 85 10 87 49
After:
10 10 15 25 32 51 53 57 85 87 90 98
2 26 37 67 71 79 81 82 84 91 94 97
10 19 49 52 66 70 75 81 85 86 87 93
由于冒泡排序的本质是要遍历整个列表,因此bubbleSort对第25行的调用将抵消使用并发的任何潜在收益。使用冒泡排序,使用并发不会提高性能。
读取文件
已经介绍了两个CPU限制的工作负载,但是IO限制的工作负载怎么办?当Goroutines自然地进出等待状态时,语义是否有所不同?看一看IO密集型的工作负载,该工作负载读取文件并执行文本搜索。
此第一个版本是的函数的顺序版本find。
清单10 https://play.golang.org/p/8gFe5F8zweN
|
|
在清单10中,您可以看到该find函数的顺序版本。在第43行,声明了一个名为found的变量,用于维护在给定文档中找到指定变量 top 的次数。然后在第44行,遍历文档,并在第45行使用read函数读取每个文档。最后,在第49-53行,在strings包中的Contains函数用于检查是否可以在从文档读取的项目集合中找到该topic。如果找到该主题,则found变量加1。
这是find函数调用read函数的实现。
清单11 https://play.golang.org/p/8gFe5F8zweN
|
|
清单11中的read函数以调用休眠一毫秒的time.Sleep调用开始。如果我们执行实际的系统调用以从磁盘读取文档,则此调用用于模拟可能产生的延迟。此延迟的一致性对于准确测量顺序版本find对并发版本的性能很重要。然后在第35-39行,将存储在全局变量 file 中的模拟xml文档解编为结构体的值以进行处理。最后,第39行将一组项目返回给调用方。
有了顺序版本后,这里是并发版本。
注意:在编写并发版本的 find 时,可以采用几种方法和选项。现在不要挂在我的特定实现上。如果您有一个可读性更高的版本,其性能相同或更好,我希望与您分享。
清单12 https://play.golang.org/p/8gFe5F8zweN
|
|
在清单12中,展示了该findConcurrent函数,它是该find函数的并发版本。并发版本使用30行代码,而非并发版本则使用13行代码。我实现并发版本的目标是控制用于处理未知数量文档的Goroutine的数量。我选择了一种使用通道来填充Goroutines池的池化模式。
有很多代码,所以我只强调要理解的重要内容。
**第61-64行:**创建了一个通道,并填充了所有要处理的文档。
**65行:**通道已关闭,因此在所有文档都被处理时,Goroutine池自然终止。
**第70行:**创建了Goroutines池。
**73-83行:**池中的每个Goroutine都从通道接收一个文档,将该文档读入内存并检查内容搜索 topic。匹配时,本地的 found 的变量增加。
**第84行:**各个Goroutine计数的总和加在一起成为最终计数。
并发版本肯定比顺序版本更复杂,但是值得吗?再次回答这个问题的最好方法是创建一个基准。对于这些基准,我使用了一千个文档的集合,并且关闭了垃圾收集器。使用该find功能的顺序版本和使用该功能的并发版本findConcurrent。
清单13
|
|
清单13显示了基准函数。这是所有Goroutines仅具有一个OS /硬件线程时的结果。顺序版本使用了1个Goroutine,并发版本使用runtime.NumCPU或8个Goroutine。在这种情况下,并发版本利用并发而没有并行性。
清单14
10 Thousand Documents using 8 goroutines with 1 core
2.9 GHz Intel 4 Core i7
Concurrency WITHOUT Parallelism
-----------------------------------------------------------------------------
$ GOGC=off go test -cpu 1 -run none -bench . -benchtime 3s
goos: darwin
goarch: amd64
pkg: github.com/ardanlabs/gotraining/topics/go/testing/benchmarks/io-bound
BenchmarkSequential 3 1483458120 ns/op
BenchmarkConcurrent 20 188941855 ns/op : ~87% Faster
BenchmarkSequentialAgain 2 1502682536 ns/op
BenchmarkConcurrentAgain 20 184037843 ns/op : ~88% Faster
清单14中的基准测试表明,当所有Goroutines仅具有一个OS /硬件线程时,并发版本比顺序版本快大约87%至88%。这是我所期望的,因为所有Goroutine都有效地共享了单个OS /硬件线程。read调用中每个Goroutine发生的自然上下文切换允许随着时间的流逝在单个OS /硬件线程上完成更多工作。
这是将并发与并行性结合使用时的基准。
清单15
10 Thousand Documents using 8 goroutines with 1 core
2.9 GHz Intel 4 Core i7
Concurrency WITH Parallelism
-----------------------------------------------------------------------------
$ GOGC=off go test -run none -bench . -benchtime 3s
goos: darwin
goarch: amd64
pkg: github.com/ardanlabs/gotraining/topics/go/testing/benchmarks/io-bound
BenchmarkSequential-8 3 1490947198 ns/op
BenchmarkConcurrent-8 20 187382200 ns/op : ~88% Faster
BenchmarkSequentialAgain-8 3 1416126029 ns/op
BenchmarkConcurrentAgain-8 20 185965460 ns/op : ~87% Faster
清单15中的基准测试表明,引入额外的OS /硬件线程不会提供任何更好的性能。
结论
这篇文章的目的是提供有关必须考虑的语义的指导,以确定工作负载是否适合使用并发。我试图提供不同类型的算法和工作负载的示例,以便您可以看到语义上的差异以及需要考虑的不同工程决策。
您可以清楚地看到,对于IO密集的工作负载,不需要并行处理就可以大大提高性能。这与您看到的CPU密集的工作相反。当涉及像冒泡排序这样的算法时,并发的使用会增加复杂性,而没有任何真正的性能优势。确定您的工作负载是否适合并发,然后确定必须使用正确的语义的工作负载类型非常重要。