栈和指针的语言机制
楔子
这是一个由四部分组成的系列文章的第一篇,该系列文章将提供对Go中指针、堆栈、堆、转义分析和值/指针语义背后的机制和设计的理解。这篇文章主要关注堆栈和指针。
四部分系列文章索引:
- Language Mechanics On Stacks And Pointers
- Language Mechanics On Escape Analysis
- Language Mechanics On Memory Profiling
- Design Philosophy On Data And Semantics
介绍
我并不打扮粉饰它,指针很难理解。当使用失当,指针会产生严重错误,甚至是性能问题。在编写并发或多线程软件时,尤其如此。很多语言试图向程序员隐藏指针也就不足为怪了。然而,如果你使用Go写软件,就没有办法避免它们。对指针没深刻的理解,你就无法编写出整洁,简单和高效的代码。
帧边界
函数在帧边界内的作用域中执行,而帧分别为每个函数提供独立的内存空间。每个帧允许函数操作它们自己的上下文,同时提供流程控制。函数通过帧指针,可以直接访问自己帧的内存,但是访问它自己帧外的内存需要非直接访问。函数访问它自己帧外的内存,则内存必须和函数共享。该机制和限制通过这些帧边界来建立,帧边界是需要首先学习和理解的。
当一个函数被调用,两个帧之间分发生转换。代码会从正在调用的函数的帧转换到被调用函数的帧。如果在函数调用中需要数据,则数据必须从一个帧转换到另一个帧。在Go中在两个帧中传递数据通过“传值”来完成。
通过“传值”来传递数据的优点是可读性。在函数调用中看到的值就是在另一端拷贝和接收的值。这就是为什么我将“传值”和所见即所得联系起来。因为你所看见的就是你得到的。所有这些允许你写代码时,不需要在两个函数中隐藏转移开销。这有助于维护一个好的心理模型,当转换发生时,每个函数调用将如何影响程序。
看下这个小程序,函数调用通过“传值”来传递整型数据:
Listing 1
|
|
当Go程序启动,运行时创建主协程来启动执行所有的初始化代码,包括 main 函数中的代码。一个协程就是一个被放置到操作系统线程上的执行路径,最终在某些核心上执行。例如在 1.8 版本,每个协程被分配初始 2048字节的连续内存块,这组成了它的栈空间。初始化栈大小在过去几年中发生了变化,这在未来可能会再次改变。
栈是重要的,因为它为帧边界提供了物理内存空间,该帧边界提供给每个独立的函数。当主协程执行清单1中的 main 函数时,协程的栈(在非常高的级别上)如下所示:
Figure 1
在列表1中可以看到,栈部分已经在 main 函数外被”框“住。该部分被称为”栈帧“,这个帧表示 main 函数在栈上的边界。帧作为当函数被调用时要执行的代码的一部分被建立。也可以看内存中的 count 变量已经被放到 main 帧内部的地址 0x10429fa4 上。
列表1还清楚地表明了另外一个有趣的点。活动帧以下的所有栈内存都无效,但是活动帧以上的内存是有效的。我需要弄清楚堆栈的有效部分和无效部分之间的界限。
地址
变量的作用是将一个名字分配给指定内存位置,以提高代码的可读性并帮助你对正在处理的数据进行推理。如果你有一个变量,则在内存中就有相应的值,同时如果在内存中有一个值,那么它必须有一个地址。在第 09 行,main 函数调用内置函数 println 打印变量 count 的值和地址。
Listing 2
|
|
使用与号 & 操作符来苑骊个变量的内存位置并不新鲜,其他语言也使用该操作符。如果你在32位架构的机器上运行代码,第 09 行的输出应该与下面的输出很类似。
Listing 3
|
|
函数调用
前往到12行,main 函数执行一个调用,执行 increment 函数。
Listing 4
|
|
做出函数调用意味着协程需要框住栈上内存的新部分。然而,事情有点儿复杂。为了成功进行函数调用,在转移期间,期望数据通过跨帧边界传递并放到新的帧上。特别是在调用期间,整型值期望被拷贝并传递。可以查看第18行的 increment 函数的声明来了解这个需求。
Listing 5
|
|
如果再将看12行的调用 increment 函数,你可以看到代码传递 count 变量的值。该值会为 increment 函数而被拷贝,传递并放入到新的帧中。记住 increment 函数仅可以直接读写它自己帧中的内存,所以它需要 inc 变量来接收,存储和访问传递给他的 count 变量的拷贝。
在 increment 函数被执行之前,协程的栈如下所示:
Figure 2
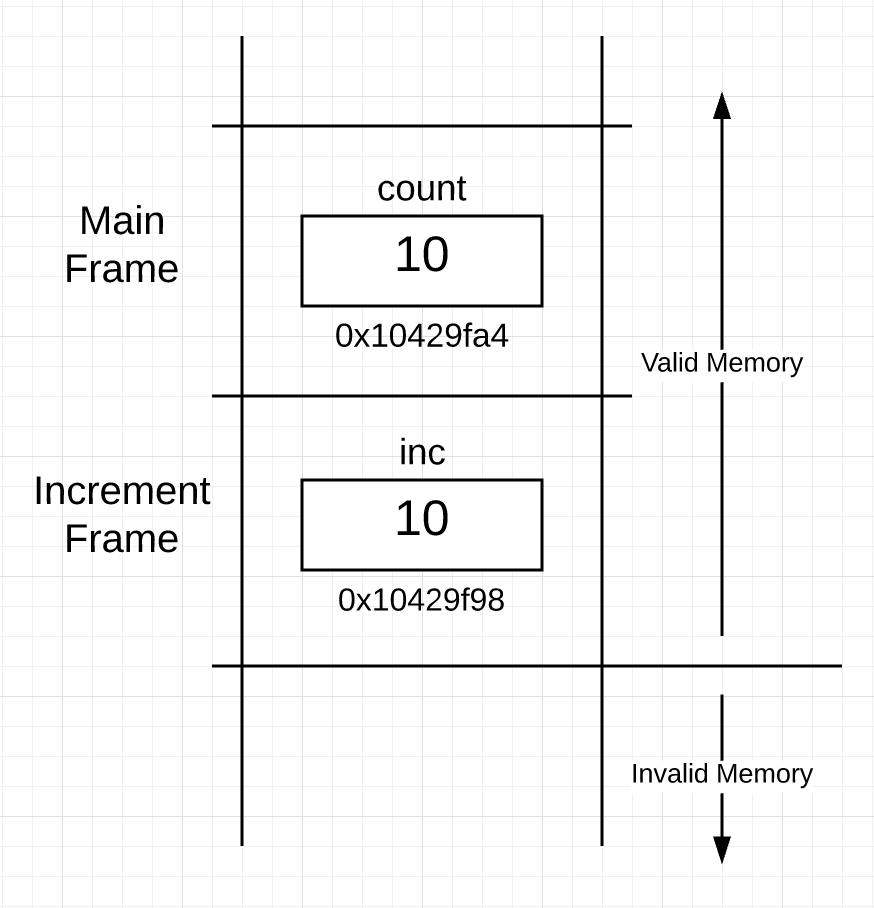
可以看到现在栈有两个帧,一个是 main 的,而另下面的另一个是 increment 的。在 increment 帧的内部,可以看到 inc 变量和它包含的值 10,是在函数调用期间被拷贝到传递过来的。变量 inc 的地址是 0x10429f98 ,在内存中位于下面,因为帧中的栈是向下的,这仅仅是实现细节,并不意味着什么。重要的是协程获取 main 帧中变量 count 的值,并使用 inc 变量将值的副本保存到在 increment 的帧中。
函数 increment 的其余代码增加并打印inc 变量的值和地址。
Listing 6
|
|
第22行的输出如下:
|
|
这就是执行这些代码行后堆栈的样子:
Figure 3
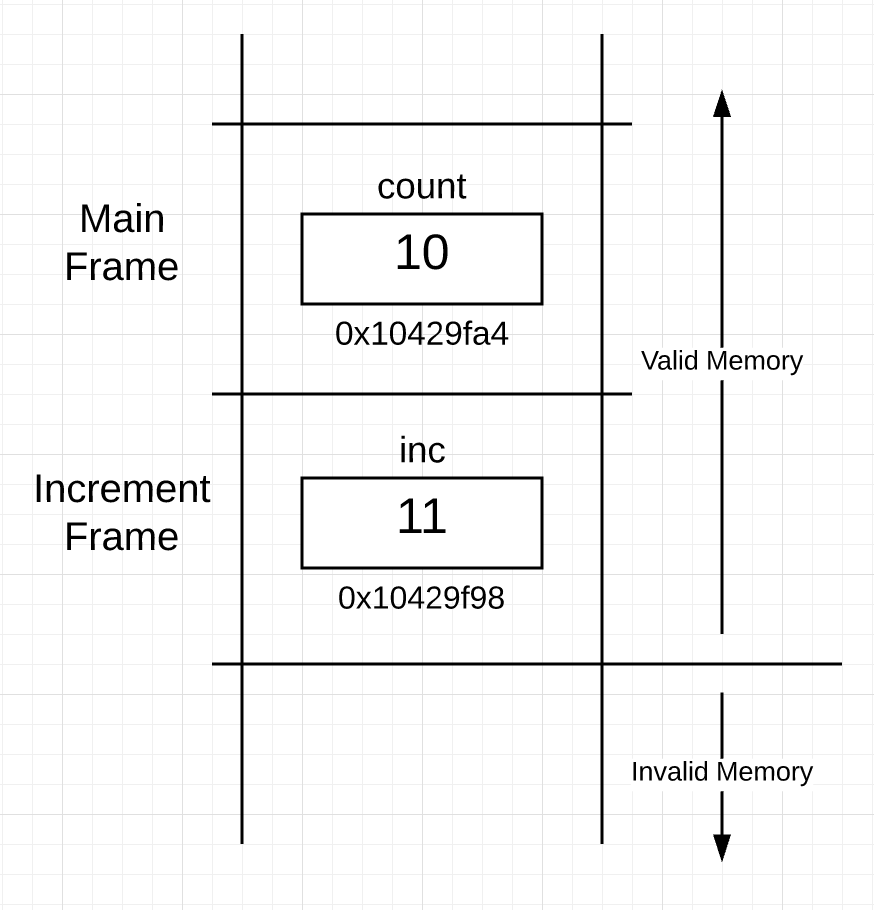
在 21 和 22 行执行之后,increment 函数返回,并将控制返回给 main 函数。然后 main 函数在第 14 行再次打印本地 count 变量的值和地址
Listing 8
|
|
程序的完整输出如下:
Listing 9
|
|
函数 main 帧中的 count 的值在调用 increment 前后是一样的。
函数返回
当函数返回,控制返回给函数调用方,栈内存实际发生了什么?简单的答案是:没有什么东西。下面是 increment 函数返回后,栈实际上内容:
Figure 4
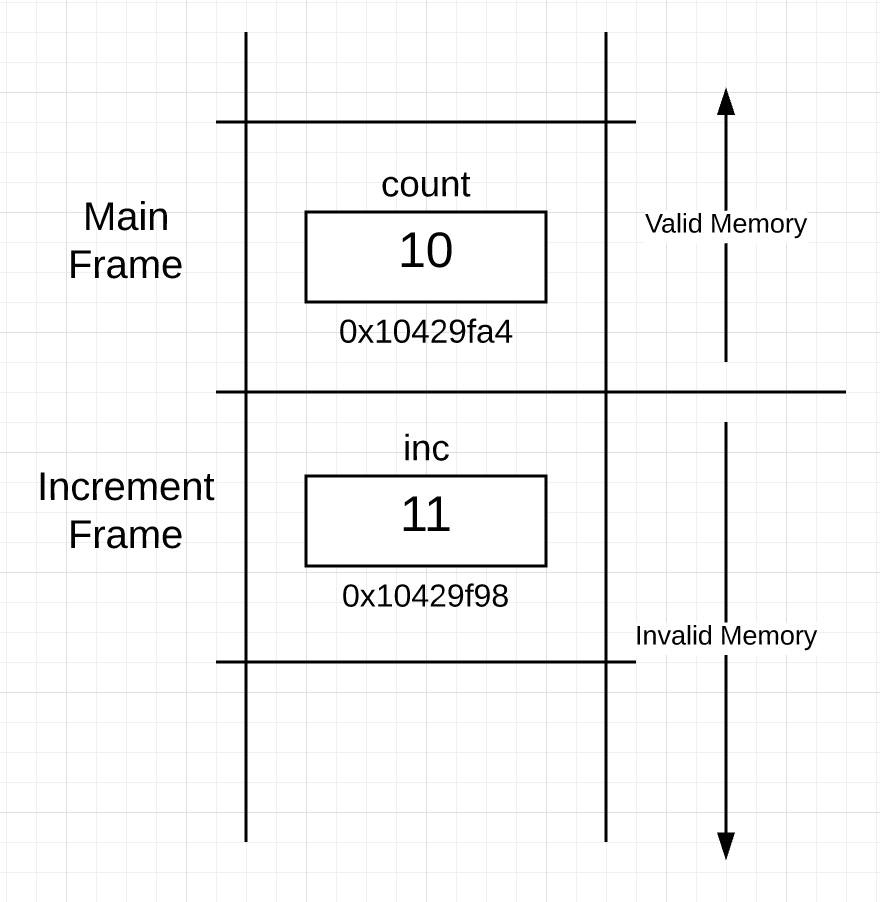
除了与函数 increment 关联的帧现在被认为是无效内存,栈看起来和Figure 3完成一样。这是因为 main 的帧现在是活跃状态。为函数 increment 而框住的内存现在是未修改的。
清理返回函数的内存被认为是浪费时间,因为你不知道该内存是否被再次需要。所以内存还保持原样。在每个函数调用期间,帧被使用,此时该帧的栈内存被清理。这通过初始化任何放到帧中的值来实现。因为所有的值都至少被初始化为它们自己的零值,栈在每次函数调用时都适当的清理他们自身。
共享值
对于函数 increment ,如果直接操作存在于 main 帧中的 count 变量是重要的,该如何办?这就是指针的用途。指针有一个作用,和函数共享值,所以函数可以读写这些值,即使这些值并不直接存在于他们自身的帧中。
如何”共享“没有从你的口中说出,你不必使用指针。当学习指针,最重要的是使用清晰的词汇表,而不是操作或语法。所以请记住,指针是为了共享的,当您阅读代码时,使用 & 操作符替换单词”共享“。
指针类型
对于您或语言本身声明的每个类型,您都可以免费获得一个完整的指针类型,用于共享。已经存在名为 int 的内置类型,因此存在名为 *int 的完整的指针类型。如果声明名为 User 的类型,则可以免费获得名为 *User 的指针类型。
所有的指针类型有同样的两个特殊。首先,他们以字符 * 作为开始。其实,他们拥有相同的内存大小和表示形式,即一个4或8字节大小的地址。在32位架构上,指针需要4字节的内存,在64位架构上,他们需要8字节大小的内存。
在规范中,指针类型被认为是类型文本,这意味着它们是由现有类型组成的未命名类型。
间接内存访问
看下这个小程序,它展示通过传值的等式传递函数调用一个地址。这将和 increment 函数共享位于 main 栈帧变量 count 的值:
Listing 10
|
|
这里和源程序相比,有三个有意思的改动。第 12 行是第一个修改:
Listing 11
|
|
此时在第12行,代码不是拷贝和传递 count 的值,而是使用 count 的地址代替。现在可以说,我和 increment 函数”共享“ count 变量。这是 & 操作符语言,”共享“。
理解这仍然是”值传递“,唯一不同的是,你传递的值是一个地址,而不是整型。地址也是值;这是在函数调用时,将被跨帧边界拷贝和传递的地方。
由于地址的值被拷贝和传递,在 increment 的帧中需要一个变量来接收和存储这个基于地址的整型。这就是18行要讲的声明整型指针变量。
Listing 12
|
|
如果你传递 User 值的地址,则该变量需要被声明为 *User。即使所有的指针变量存储地址的值,但他们不能传递任意地址,仅能传递与指针类型关联的地址。这是重要的,原因是共享一个值是因为接收函数需要执行读写该值。你需要值的类型信息以读写它。编译器需要确保只有值与正确指针类型才可以在函数中共享。
下面是在函数调用 increment 之后的栈内容:
Figure 5
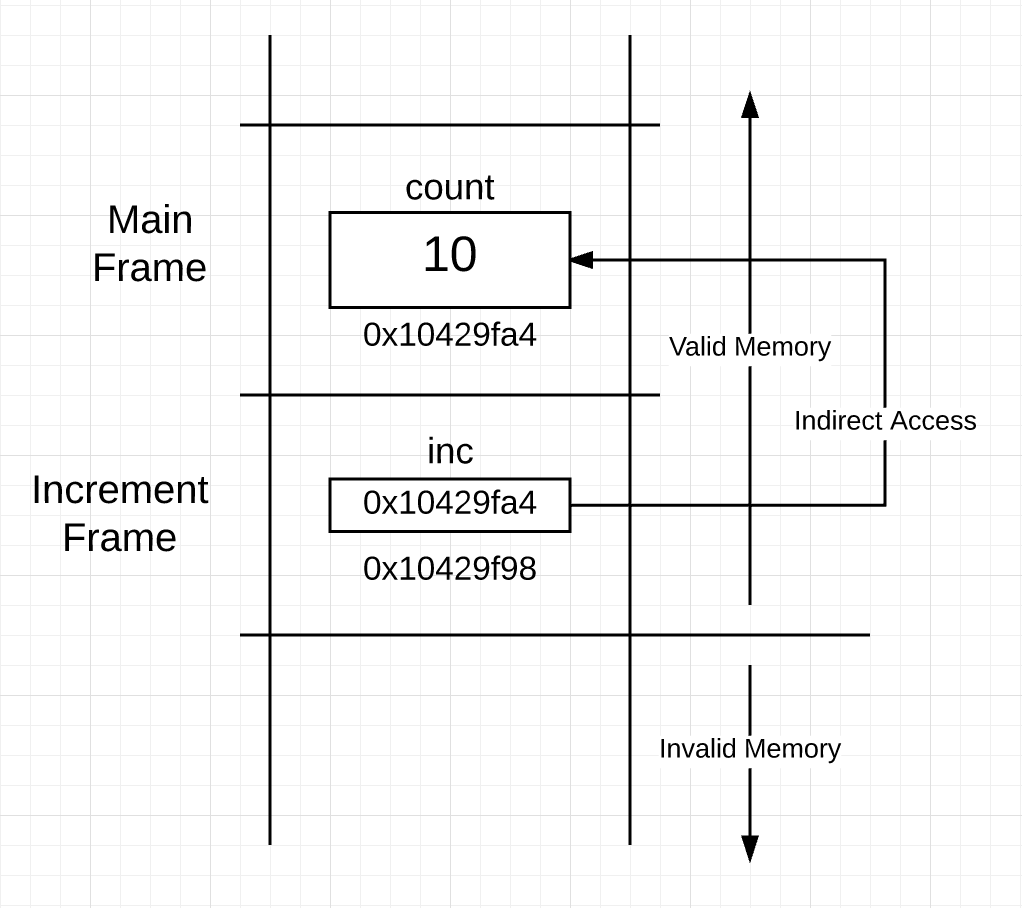
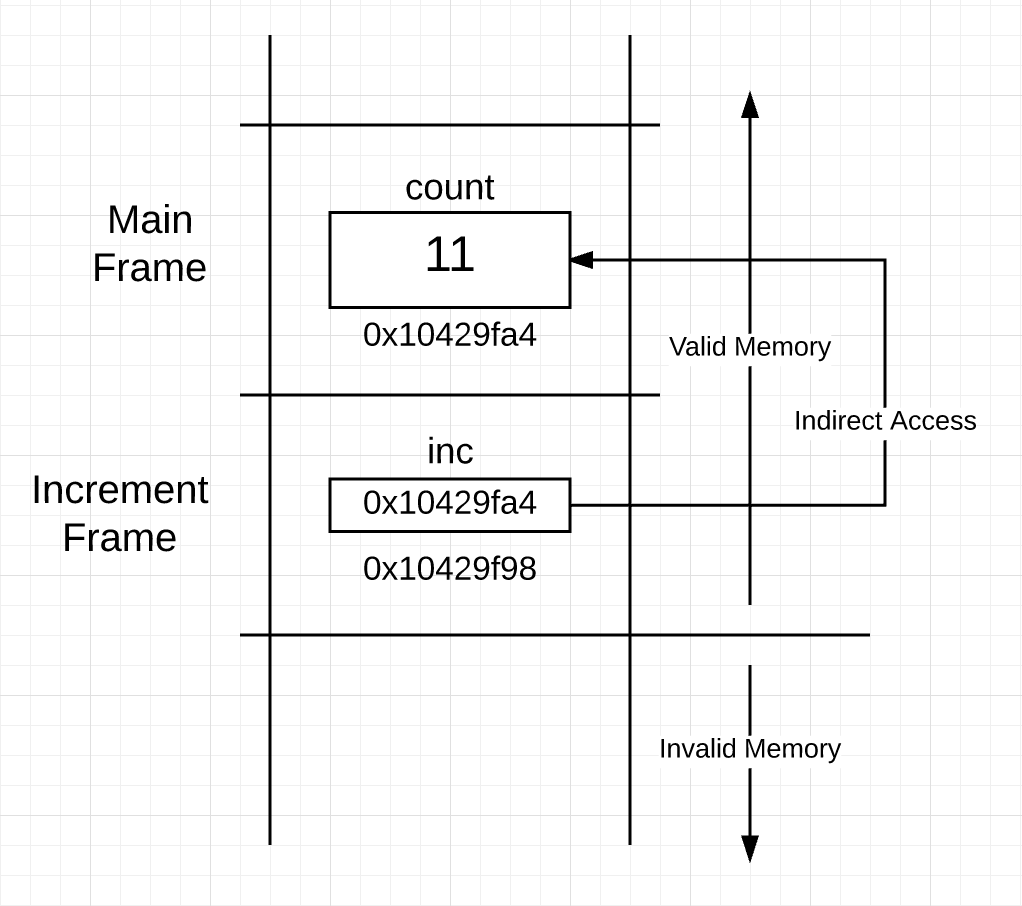
可以在 figure 5 中看到,当使用地址作为值执行“传值”时栈的样子。increment 函数框架内的指针变量现在指向 count变量,该变量位于 main 函数框架内。
现在使用指针变量,函数可以间接读,修改,写位于 main 帧内的 count 变量。
Listing 13
|
|
此时,字符 * 充当运算符并作用于指针变量。使用 * 作为操作符,意味着”指针指向的值“。指针允许间接内存访问它使用的函数帧以外变量。有时该间接读或写被称为指针的解引用。函数 increment 的帧内必须有可以直接读取的指针变量来行使间接访问。
现在在 表6 可以看到在 21 行的执行之后的栈情况
Figure 6
下面是最终的输出:
Listing 14
|
|
可以看到指针变量 inc 的值和变量 count 的值是一样的。这设置了共享关系,允许间接访问帧外的内存进行替换。当通过 increment 函数的指针进行了写操作,当控制返回时,在 main 函数中是可见的。
指针变量并不特殊
指针变量并不特殊,因为他们和其他变量一样也是变量。他们朋内存指定并持有一个值。碰巧的是所有的指针变量,除了他们指向的类型的值,通常是同样的大小和表现。可以造成困惑的是 * 字符作在代码中为操作符,被用来声明指针类型。如果你辨别类型声明和指针操作,这将有助于减少困惑。
结论
这篇文章描述了指针背后的目的,和Go中栈和指针的机制。这是理解机制,设计哲学和指导持久性和可读性代码的第一步。
下面是总结:
- 函数在帧边界作用域中执行,域边界为每个对应的函数提供独立的内存空间。
- 当函数被调用,在两个帧中有一个转移和替换。
- 通过”传值“来传递数据的一个好处是可读性。
- 栈是重要的,因为他为每个独立的函数的帧边界提供物理内存空间。
- 所以活动帧下面的下面是无效和,而活动帧上面的内存是有效的。
- 进行函数调用意味着goroutine需要在堆栈上构建一个新的内存段。
- 在每个函数调用期间,当使用了帧,帧的栈内存被清理。
- 指针有一个目的,和函数共享值以便函数可以直接读写值,即使值不是直接存在它自己的帧中。
- 通过人或语言本身声明的每个类型,将免费获得一个可以直接使用的完整的指针类型。
- 指针变量允许间接访问它使用函数帧外的内存
- 指针变量并不特殊,因为他们和其他变量一样也是变量。他们拥有指定的内存并持有变量。